2022年7月3日,湖南大学金融与统计学院举办了2022年大数据统计学与计量经济学研讨会。会议开幕式由湖南大学金融与统计学院副院长李海奇教授主持。李海奇副院长在致辞中代表湖南大学金融与统计学院对莅会嘉宾表示热烈欢迎,向各位参会嘉宾介绍了学校、学院和学科的历史和发展情况以及本次会议的议程情况。

本次会议邀请到华东师范大学统计学院研究员谌自奇、首都经贸大学国际经济管理学院副教授陈烨、厦门大学数学科学学院副教授胡杰、东北财经大学高等经济研究院助理教授吕耀廉、北京大学光华管理学院副教授涂云东、中国人民大学经济学院副教授王霞、北京师范大学统计与数据科学中心副研究员谢传龙、上海交通大学生物信息学与生物统计学系副研究员张岳、湖南大学金融与统计学院副教授谭发龙和助理教授陈汉带来了精彩报告。
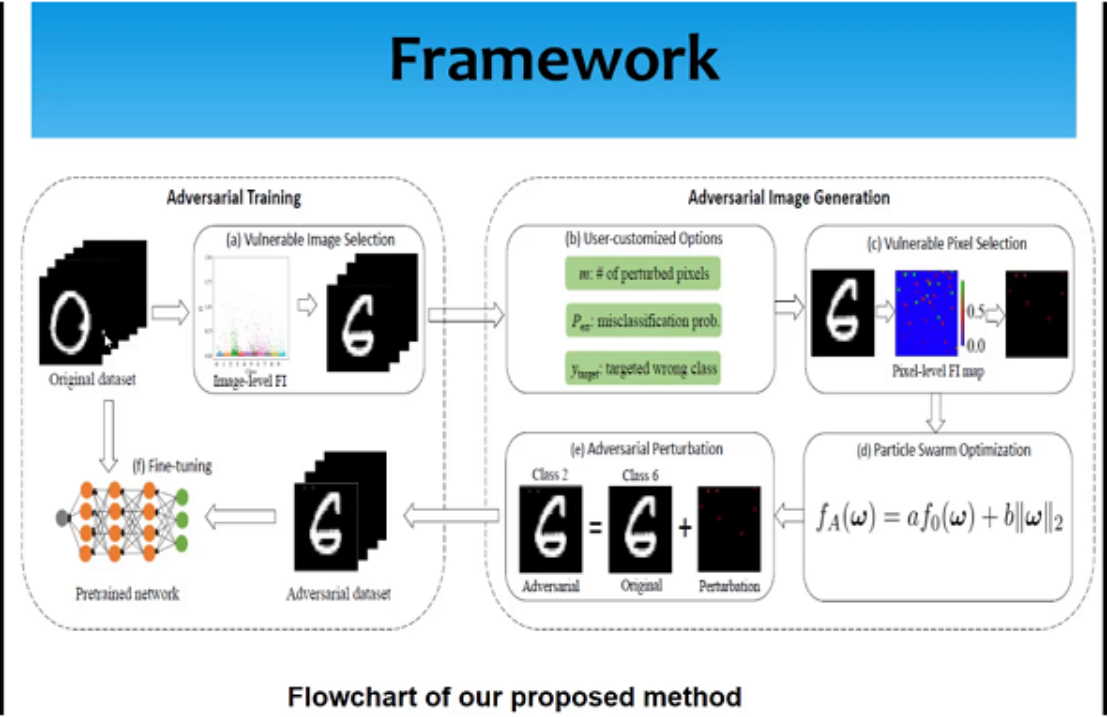
谌自奇研究员的报告题目是“mFI-PSO: A Flexible and Effective Method in Adversarial Image Generation for Deep Neural Networks”。在深度神经网络图像分类任务中,通常若对图片添加微小的扰动,深度神经网络会丧失分类能力。因此,为了提高深度神经网络的稳健性,谌自奇研究员提出了一种mFI-PSO的方法。该方法根据定制化需求识别出图像数据集中的敏感图像,然后对这些图像进行攻击生成对抗样本,最后将这些样本加入原始数据集重新训练模型,最终可以得到稳健性更好的模型。实验表明,其提出的方法在对深度神经网络生成定制化的对抗样本具有非常好的表现,优于目前大部分的研究方法。
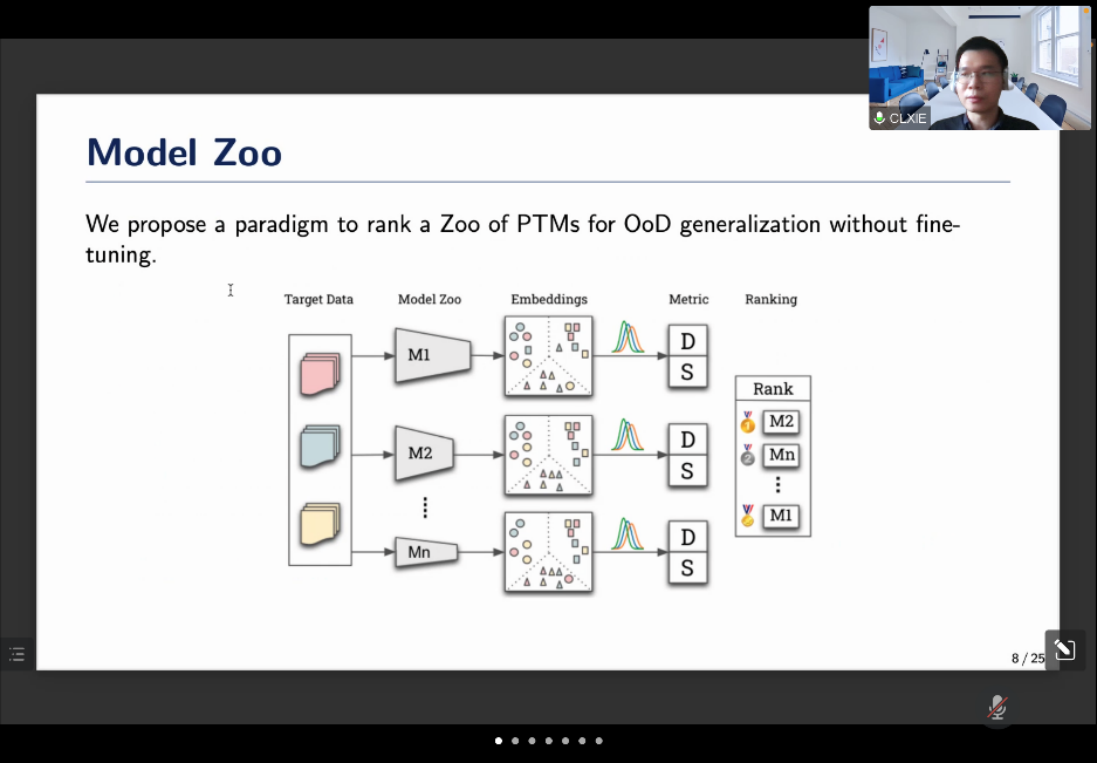
随后,谢传龙副研究员报告了他最新的研究工作《Exploting model zoo for out of distribution generalization》。Out of distribution generalization(OOD)问题是指测试样本与训练样本分布的不同而引起的模型泛化问题,大多数学者通过预训练来提高OOD泛化能力。在常用的深度学习的框架下,通常能找到很多针对数据集的训练好的预模型。谢传龙副研究员在其报告中提出一种方法,能够衡量模型在不同数据间的迁移效率,包括correlation shift和discriminability,对备选模型进行打分和排名,能针对特定数据集衡量众多预训练模型的泛化能力,以便快速地找到适用于该数据集的最优预训练模型。
张岳副研究员报告的题目是“区间删失Cox模型中时变系数的估计与检验”。在估计区间删失Cox模型中时变系数时,生存函数里会出现很难处理的积分项,给理论证明和计算都带来了很大的困难。为此,张岳副研究员提出使用了sieve方法,利用B样条函数逼近未知的时变系数。基于sieve方法,他们提出了时变系数Cox模型的似然估计,证明了估计量的相合性,建立了最优收敛速度和渐近正态性。最后利用CHLHS关于中国老年人的调查数据,该方法具有良好的效果。

谭发龙副教授的报告题目是“Weighted residual empirical processes, martingale transformations, and model checking for regressions”。由于传统模型检验方法会遭受维数祸根问题,谭发龙副教授提出了一种基于加权残差经验过程及其鞅变换的新方法。该方法基于残差的示性函数来避免维数祸根问题,并且鞅变换使得该方法是渐近分布自由的,从而避免了维数祸根问题;进一步研究可以发现基于鞅变换的方法只能检测n^(-1/4)速度趋于原假设的局部备择假设,这一发现完全不同于现有文献中的结论。最后通过数值模拟和实际数据的来说明新的检验统计量的有效性。

胡杰副教授报告的题目是“Beyesian statistical analysis of stochastic phenotypic plasticity model of cancer cells”。胡杰副教授首先介绍了癌细胞表型可塑性的背景,虽然相关的模型在数学性质方面已经得到了广泛的研究,但对参数估计和模型选择的统计分析仍然非常缺乏,因此胡杰副教授提出了一种蕴含连续时间信息的贝叶斯方法,用于处理癌症干细胞(CSCs)转化概率的均值和方差信息的数据集,并用大量的模拟实验证明了该模型和算法的有效性;最后将该方法应用于SW620结肠癌细胞的数据,研究发现相对于传统的癌细胞分级模型,模型选择更倾向于表型可塑性模型。
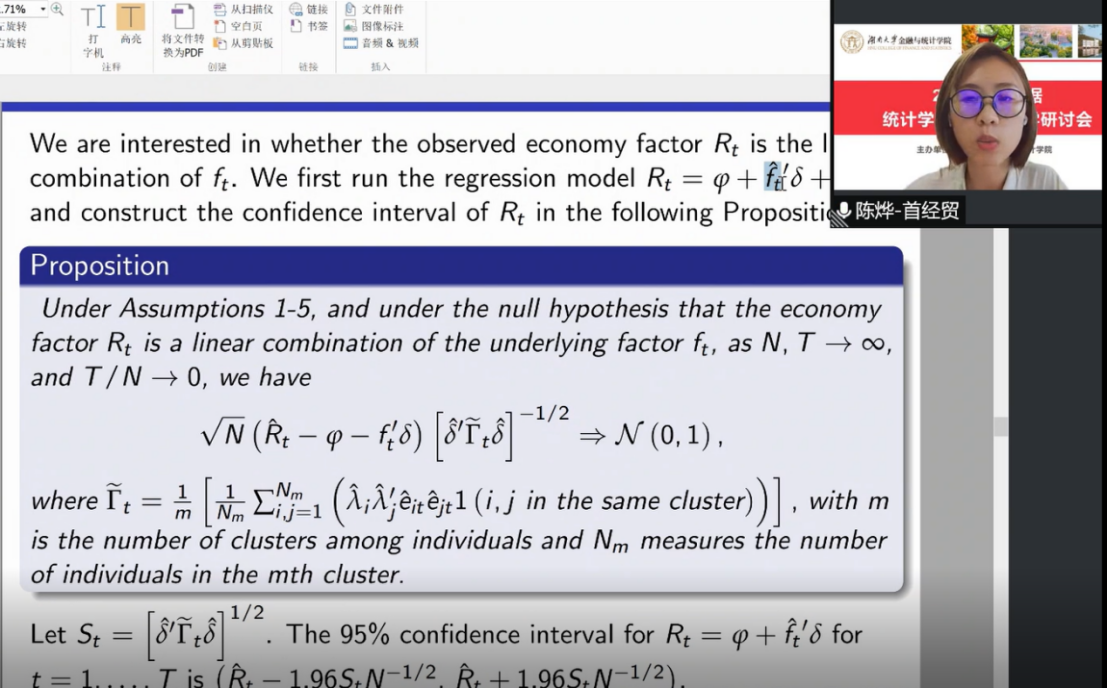
吕耀廉助理教授报告的题目是“Robust Inference for Predictive Regression under Persistent Errors。吕耀廉助理教授首先指出,当预测回归模型中随机扰动项含有高持续性时,现有的显著性检验统计量会产生严重的尺寸扭曲问题。他们发现当随机扰动项服从近单位根特征过程或中等偏离过程时,Bonferroni置信区间法、基于柯西估计量的检验统计量和基于自辅助工具变量法的Wald检验统计量无法提供有效的渐近推断。为了解决高持续性随机扰动产生的过度拒绝问题,他们提出了基于序列自相关Cochrane-Orcutt修正的稳健推断方法。由此产生的检验统计量具有渐近卡方分布,并且在近单位根和中等偏离的随机扰动情形下,均具有优良的统计性质。最后,他指出稳健性检验方法可运用于对房价的实证研究。

涂云东副教授报告了他们最新的研究成果《Shrinkage estimation of multiple factor model》。他们将门限效应引入因子模型,将 Group Fused Lasso 方法应用于对门限因子模型多个门限的识别和估计,并证明了门限值、门限个数及因子个数的估计量的大样本性质。涂云东副教授介绍到,通过对数据的重新排序,门限因子模型的估计可以转化成多结构变点因子模型的估计,使用 Group Fused Lasso 方法对变点个数和变点值进行压缩估计,可以得到对应的门限个数和门限值的估计。进一步,涂云东副教授提出了两步估计方法,使用信息准则对为对门限个数进行筛选,这一筛选过程使用 Backward Elimination Algorithm 实现。
王霞副教授报告的题目是《Specification tests for time varying coefficient models》。王霞副教授从经济学的应用出发,引出时变系数模型设定,同时介绍了目前主流的三种对时变系数的设定。对于应用哪一种时变系数设定提出了分析和检验。她指出,在现有的金融数据研究方面,通常会假设模型系数是时变的,而且一般有三种时变系数的设定:随机平稳过程、随机非平稳过程、时间t的函数。在应用这三种时变系数的设定时,通常会被问到选取其中一种设定的理由。为了区分这三种设定的应用场景,她以随机平稳过程作为原假设提出了一系列假设,通过OLS获取残差项构造检验统计量来检验是否拒绝原假设;若拒绝原假设,则进一步通过非参数估计方法获取残差项构造检验统计量来检验时变系数是随机非平稳过程还是时间t的函数。王霞副教授将该方法应用到多个场景中,验证了方法的有效性,为时变系数设定的应用起到了指示性的作用。

陈烨副教授报告的题目是“Mixed Dynamic Factor Modeling applied to Explosive House Prices”。陈烨副教授从全球各地的房价上升现象出发,从计量经济学的角度,对房价上升的原因进行了分析和总结。她指出,一方面,随着经济的发展,人们对美好生活的不断追求,在城市中买房带来了需求量的上升;另一方面,买房需求会随着各种政策的变化而变化,尤其是利率的变化。接下来,她构建了关于房价的混合动态因子模型,其中包含三类因子:驱动房价迅速上升的因子、服从单位根过程的因子、平稳过程的因子。她利用信息准则与主成分分析分别估计出因子个数与因子载荷。在给定一系列假设后,得出了因子的渐近结果。陈烨老师将这个方法应用到我国与澳洲的房价数据分析中,从数据分析的角度分别得出了引起房价迅速上升的原因。这个方法对分析房价迅速上升的原因分析做出了贡献。
陈汉助理教授报告的题目是“Multivariate Stochastic Volatility Models based on Generalized Fisher Transformation”。陈汉助理教授研究的问题是对收益率序列建立多元波动率模型。他们指出在单变量模型中,一个常见的做法是对数据作对数变换确保时变波动率的符号为正。但是对于多元波动率模型,如何保证时变协方差矩阵是正定的是一个重要的研究问题。他们提出了基于广义费雪变换的多元随机波动率模型。与文献中的方法对比,该模型具有易解释、对于相关系数的估计不受数值限制等特点。他们提出使用Particle Gibbs Ancestor Sampling方法来做统计推断。进一步地, 他们展示了大量数值模拟结果,结果表明新提出的方法具有良好的有限样本表现。最后,通过考虑多个汇率序列的来说明所提方法的应用。


读研在金统

金大团


